Битва титанов или Google начинает, и выигрывает
Алексей Юдин, эксперт по информационной безопасности Positive Technologies
Говоря на чистоту, я не хотел публиковать озвученные в этой статье данные, прежде всего, в связи с их высоким "флеймообразующим" потенциалом, тем более что с технической точки зрения она достойна разве что анекдота. Но по настоянию Александра Антипова, чьи аргументы оказались диаметрально противоположны моим - чем больше обсуждения, тем лучше - информация была скомпилирована в виде статьи и представлена на суд читателей.
Итак,
Битва титанов или Google начинает, и выигрывает
Поисковые машины являются неотъемлемой частью сети Internet. Для большинства пользователей они и есть Internet - кроме двух или трех сайтов, URL которых они знают наизусть, все остальные обращения к Сети происходят через "искалки".
В связи с этим поисковые машины пользуются огромным доверием со стороны пользователей, и, получив по почте/ICQ/ и др средствам общения ссылку на поисковую машину, пользователь смело на нее нажимает. Дошло уже до того, что вместо сакраментального "RTFM" все чаще пишут "Use Google" или спроси у Яндекса. Кроме непосредственно поиска Web-страниц поисковые машины могут использоваться и для других целей, например: поиск изображений и перевод статей, смены адреса центра управления бот-сети в случае пропадания основного и т.д. и т.п.
В последней версии Internet Explorer 7.0 компания Microsoft добавила возможность отправки поисковых запросов напрямую из окна браузера. Поскольку в качестве поисковой машины по умолчанию IE использует не привычный Google, а платформу для будущих online сервисов Microsoft - live.com было решено сравнить эти два решения с точки зрения безопасности приложений.
Казалось бы какие уязвимости можно найти в поисковых машинах? Времена, когда поиск по ключевому слову alert('yep, am h0ker!') приводил к однозначному появлению диалогового окошка давно (надеюсь) канули в лету. Мощнейший backend надежно скрыт от пользователей, а фуззинг поисковых роботов является отнюдь не тривиальной задачей (если не считать локальных «искалок», но об этом позже). Остается пойти по накатанному пути и послать менеджеру по продаже контекстной рекламы ссылку на Google...
Мне повезет?
Первая из обнаруженных проблем лежала в спорной области различных методов использования функциональных возможностей (Abuse of Functionality в классификации Web Application Security Consortium Thread Classification www.webappsec.org/projects/threat/).
В некоторых поисковых машин присутствует возможность перехода на первую из найденных ссылок. В Google она называется "Мне повезет!" ("I'm Feeling Lucky").
Google определяет, что данная функция была задействована по наличию параметра btnG, передаваемого в URL.
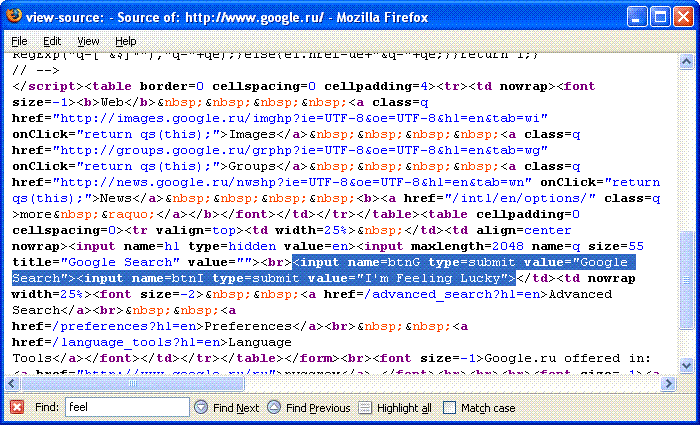
Поскольку степень "разборчивости" современных поисковиков достаточно велика, всегда можно подобрать запрос таким образом, чтобы первым в списке оказывалась нужная нам страница, на которую браузер пользователя перейдет при клике на ссылке, например: www.google.com/search?q=WebViewFolderIcon+setSlice%28%29+D0wnLoad+%26+Exec+POC+site%3Amilw0rm.com&btnI=aa.
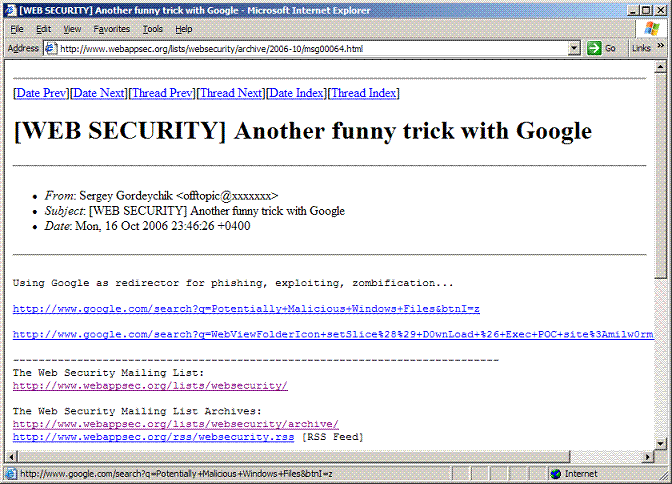
Ну и что в этом особенного, спросит читатель относящийся скорее к white- чем к black? Да собственно говоря - ничего, просто редиректор с "кликабельностью" равной практически 100%. Злоумышленник устанавливает (или заимствует) Web-сервер, дожидается пока тот индексируется в поисковой машине, заливает на него дроппер/экслойтер/загрузчик для очередного 0-day в IE, после чего рассылает ссылку по почте/форумам/IM и так далее. Пользователь, видя, что ссылка ведет на "родную" поисковую машину спокойно по ней переходит, а там действительно Дима Билан с Газмановым!!!
Для защиты от подобных неприятностей желательно использовать стандартные методы противодействия атакам типа "Подделка HTTP-запроса" (Cross-Site Request Forgery, CSRF), а именно:
- анализировать значение параметра Referer заголовка HTTP;
- добавлять в форму со скрытым полем, привязанным к сессии пользователя.
В случае с поисковыми машинами в качестве скрытого идентификатора вполне можно использоваться значение hash-функции от IP-адреса и серверного секрета. Лучше применять первые три октета, дабы не обижать пользователей некоторых провайдеров, использующих массивы proxy-серверов. Это позволит отсечь запросы, пришедшие с внешних сайтов. Конечно, зная адрес жертвы злоумышленник может подделать и идентификатор сессии, но эффект массовости будет потерян.
Как уже говорилось раньше – в поисковой машине от Microsoft такой функции нет, а значит, и нет проблемы:

Слово и кисть
Идея поиска изображений в Internet меня всегда завораживала. Конечно, современное состояние вопроса ещё достаточно далеко от описанного в "Паутине" (www.fuga.ru/shelley/pautina/pautina.htm) поиска по реальному изображению, и на запрос о "дигидромоноксид" можно наткнуться и на Диму Билана с Газмановым и Тату в придачу, но все же.
Результаты поиска изображений и у Google и у Microsoft отображаются практически идентично - окно браузера разделяется на фреймы, верхний из которых содержит информацию об изображении, генерируемую сайтом, а в нижнем отображается оригинальный сайт. Правда у Microsoft все оформлено гораздо красивее и разнообразные AJAX – штучки призваны показать достоинства Internet Explorer в качестве платформы для счастливого приобщения WEB 2 и другим маркетинговым терминам.
Но как вы понимаете, у этого есть и обратная сторона. Например:
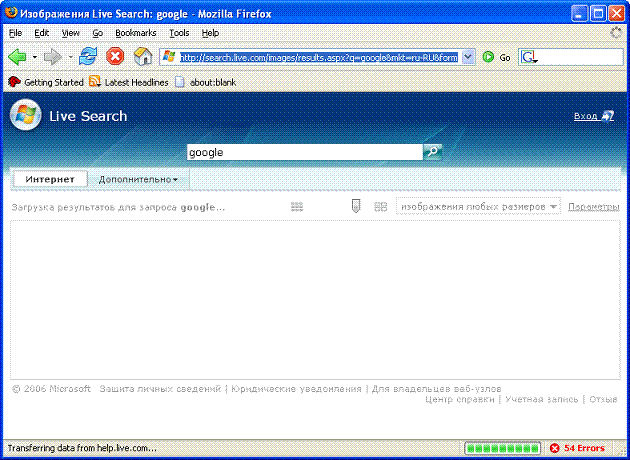
Первое, что приходит в голову при виде подобной конструкции, это проверка на наличие уязвимости типа "Подмена содержимого" (Content Spoofing). Меняем значение параметра imgrefurl для Google или su для live.com на URL своего любимого сайта, и вуаля - чудо свершилось.
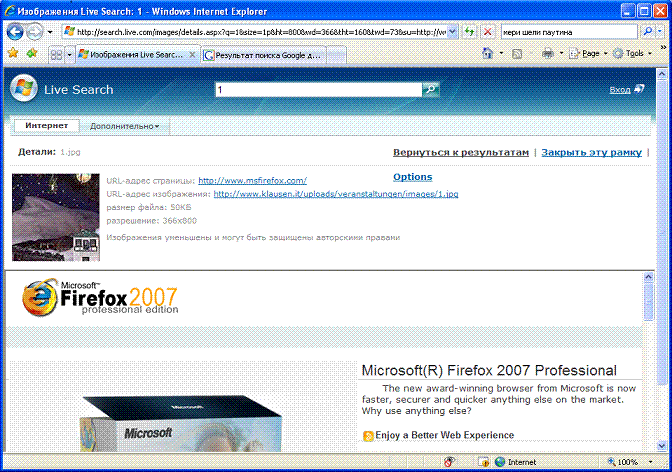
Хотелось бы поблагодарить Варфаломея Кащеева, который указал мне на эту особенность работы Google.
Счет
Йес – Икс Эсс Эсс!
Подмена содержимого достаточно тесно связанна с межсайтовым выполнением сценариев (Cross-Site Scripting, XSS). Однако риск, связанный с XSS выше, поскольку внедряемый сценарий выполняется в контексте уязвимого сервера и следовательно злобный скрипт имеет доступ к кукам, спамам и прочим хакам. Однако от толку мало, поскольку в данном случае сценарий отработает не в зоне безопасности сайта. Необходимо искать другие цели.
С Google все оказалось достаточно хорошо (или плохо, с какой стороны посмотреть). Сам сайт сконструирован таким образом, что не использует внешних элементов в тегах, и кроме того, он не очень адекватно реагирует на попытки использовать различные трюки для обхода фильтрации – просто отправляет на заглавную страницу. Не так давно во всех ответах серверы Google стали явно указывать UTF-8 что свело на нет многочисленные варианты межсайтового выполнения сценариев через кодировку UTF-7.
У Microsoft все несколько хуже. Если мы вернемся к функции просмотра найденных изображений и более детально проанализируем соответствие URL и элементов страницы, то получим примерно следующую картину:
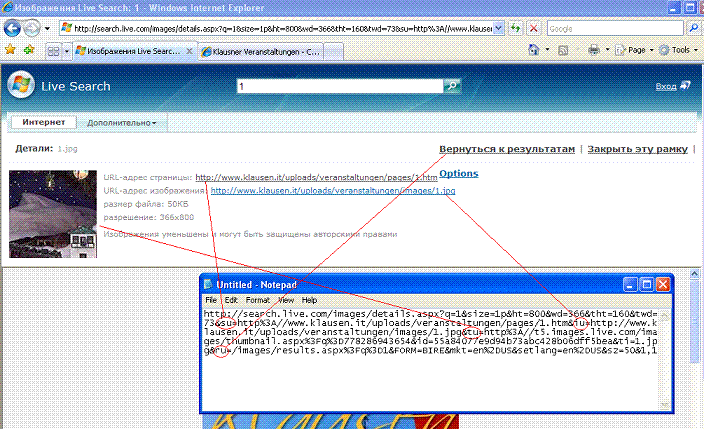
То есть, параметры URL на прямую используются для формирования таких потенциально опасных с точки зрения XSS элементов как и . Первая же попытка привела к ожидаемому результату:
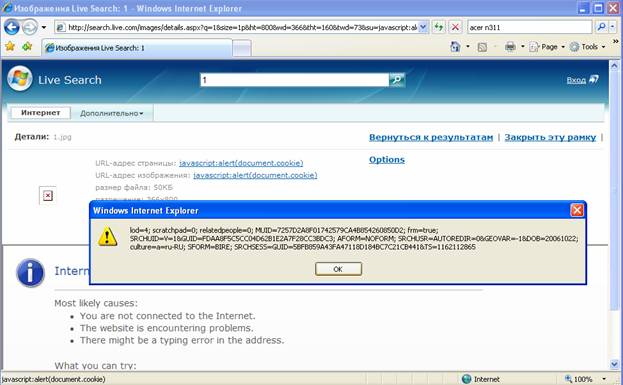
Более того, для XSS оказались уязвимы все четыре управляющих элемента, соответственно мы получили два промаха Google и пять Microsoft:
Надеюсь, читать эту статью было не менее забавно, чем писать. Удачи.
ЗЫ.
После того, как статья была написана, оказалось, что оба поисковых сервера содержат ряд сценариев, могущих использоваться как редиректоры без лишних трюков. Например:
www.google.com/url?q=www.maxpatrol.com или
search.live.com/act2.aspx?q=49&b=1&url=www.ptsecurity.ru.
Уязвимость сайта Microsoft относится к классу Response Splitting, однако эксплуатация её для подмены содержимого страницы затруднена. Это связанно с тем, что попытки добавить данные в тело ответа пресекаются сервером.
ЗЗЫ.
Подозреваю, что у части читателей возникнет вопрос о правомерности подобной публикации. Чтобы развеять их сомнения, сообщаю: информация об этих проблемах была передана Google и Microsoft (MSRC 7022, MSRC 6991) несколько месяцев назад. Причем Microsoft успел устранить некоторые из них.
www.securitylab.ru